This application is designed for environmental audio classification and aims to assist individuals who are deaf or have severe hearing loss by focusing on environmental and urban sounds. To get started with this project, follow the steps below. Please note that this application is meant to run locally, as all audio capturing and analysis processes are performed on the server.

git clone https://github.com/Joal84/audio-class.git
cd audio-class
npm install
cd flask-server
pip install -r requirements.txt
npm run dev
Purpose: This application is designed for environmental audio classification, with a focus on assisting individuals who are deaf or have severe hearing loss, particularly in recognizing environmental and urban sounds.
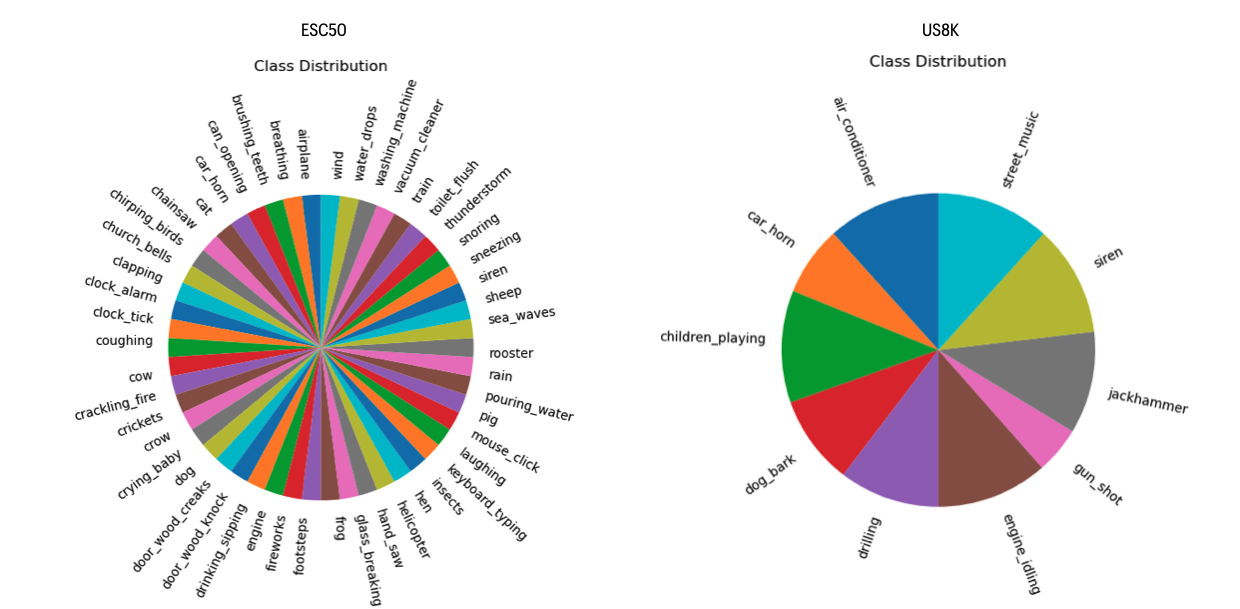
Data Sources: The classification model was trained using two datasets:
- ESC50: 50 classes, 40 recordings per class, each lasting 5 seconds.
- us8K: 10 classes, 8732 total recordings, each with a duration of less than 4 seconds.
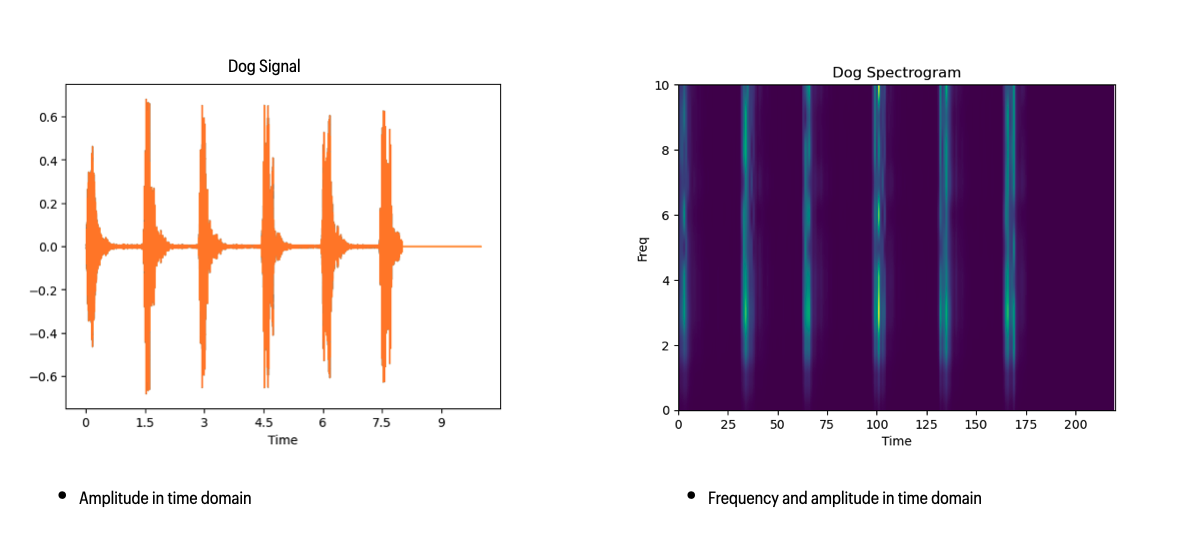
- The application uses the "Librosa" library to load all audio files.
- All audio files have a sample rate of 44.1 kHz.
- Audio signals are captured in 1-second chunks. If a sound has a smaller duration, it's padded with 0's. Longer sounds are truncated.
- The audio data is reshaped into a 2D array.
- Spectrogram extraction uses the Normalized Radial Diffusivity Transform (NRDT) algorithm to calculate diffusivity at different time delays.
- Various parameters like flag, window (w), and channels are set for different spectrogram extraction approaches.
- The CNN model uses the "Selu" activation function to mitigate vanishing and exploding gradient problems.
- It monitors validation accuracy and saves the best model checkpoint per epoch.
- Model evaluation involves training both datasets on the same model, achieving high accuracy levels of 94% (esc50) and 97% (us8k) on test data.
- The application utilizes the "pyaudio" library for managing live audio input into Python.
- You can choose which microphone to be used by changing
input_device_indexvalue, inprediction.py, to curresponding number of the device you would like to use.
Issues with live audio input are often related to the "chunks" of audio sent to the model for prediction.
A gate system has been implemented to automate the start and end of the recording process, helping to address these issues. A gate threshold in prediction.py can be ajusted for fine tuning.