Spark with Scala 101 workshop.
It will cover basic aspects of Spark, especially:
- Execution model.
- Memory model.
- Resilient Distributed Datasets (
RDD). - Transformations (lazy) VS Actions (eager).
Dataset&DataFrame.
For this workshop you only need:
- A fork of this repo
- A Java Development Kit (JDK) 8 / 11
- sbt installed
- An IDE of your preference
Spark is a "unified analytics engine for large-scale data processing".
Which basically means it is intended for processing datasets that won't fit on the memory (RAM) of a single machine. Thus having to be partitioned across many machines; implying a distributed processing.
To accomplish this, Spark uses a traditional 1-Master N-Workers cluster architecture.
The master is called the Driver, which holds the SparkContext (and the SparkSession),
and the workers are called Executors, which are responsible of keeping
the data and running tasks to process / transform it.
The SparkContext is in charge of communicating with a Cluster Manager
to allocate resources for the Executors,
and it sends the processing logic from the Driver to the Executors.

Spark, Cluster Mode: https://spark.apache.org/docs/latest/cluster-overview.html
The memory of a Spark program is divided into multiple frames:
- System memory - the real amount of memory available to the runtime environment.
- Heap - the actual amount of memory given to the JVM running the Executor - this can't be all the system memory since you also need some space for other things like: the Stack, the operating system, buffer cache, etc.
- Reserved memory - a fixed amount of 300 MB that Spark reserves for itself to recover from OOM errors.
- User memory - a fraction of the remaining Heap memory that will be left for user data structures and Spark metadata.
- Spark memory - The remaining of the Heap which will be used by Spark
- Is divided in two groups: The Execution & Storage,
the groups division is not fixed;
thus Execution can reclaim Storage space (eviction).
However, you can specify a fraction of the memory that will be safe of eviction.
Spark, Memory Tuning: https://spark.apache.org/docs/latest/tuning.html#memory-management-overview
Spark, Memory Management: https://spark.apache.org/docs/latest/configuration.html#memory-management
The RDD is the main abstraction provided by the framework.
A RDD can be seen as regular Scala collection of elements,
with the particularity of being partitioned across the nodes of the cluster;
thus being processed in a distributed fashion.
A RDD can be created from parallelizing an existing local collection,
or by reading an external dataset.
You processes your data by applying common functional transformations,
like map, flatMap, filter, reduce, etc.
RDDs are immutable, which means that when you apply one of these transformations,
you get back a new RDD.
Additionally, RDDs transformations are lazy,
that means they don't execute anything when called.
Instead, they create a DAG that represents your pipeline; which will be run latter.
There are another kind of operations provided by RDDs,
these will return plain values, instead of another RDDs.
These are called actions and are eager.
Meaning they will run the RDD DAG, executing each of the planned transformations,
in order to compute the resulting value.
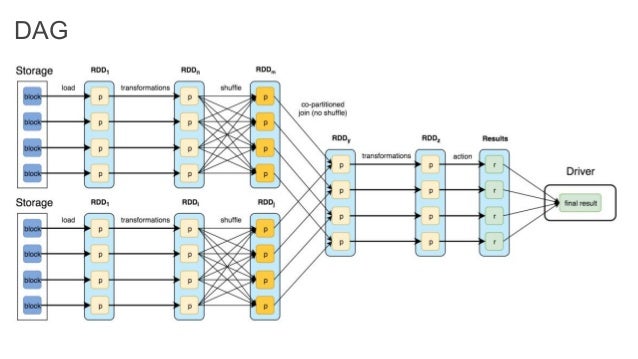
Apache Spark in Depth: Core Concepts, Architecture & Internals: https://www.slideshare.net/akirillov/spark-workshop-internals-architecture-and-coding-59035491
A simple cheat sheet of the most common functional transformations provided by Spark.
map: Applies a function to each element of the collection.
def map[A, B](collection: C[A])(f: A => B): C[B]
RDD(1, 2, 3).map(x => x + 1) === RDD(2, 3, 4)flatMap: Applies a function to each element of the collection, and then flatten the results.
def flatMap[A, B](collection: C[A])(f: A => C[B]): C[B]
RDD(1, 2, 3).map(x => List.fill(x)(x)) === RDD(List(1), List(2, 2), List(3, 3, 3))
RDD(1, 2, 3).flatMap(x => List.fill(x)(x)) === RDD(1, 2, 2, 3, 3, 3)filter: Returns the elements of the input collection that satisfy a given predicate.
def filter[A](collection: C[A])(p: A => Boolean): C[A]
RDD(1, 2, 3).filter(x => (x % 2) != 0) === RDD(1, 3)fold: Reduces all the elements of the input collection to a single value, using a binary function and a starting zero value.
def fold[A](collection: C[A])(z: A)(op: (A, A) => A): A
RDD(1, 2, 3).fold(0)(_ + _) === 6There is a variation of
foldwhich allows to change the output type calledaggregate
Datasets and DataFrames are higher level abstractions provided by Spark.
They provide several ways to interact with the data, including SQL & the Datasets API.
They provide Spark with more information about the structure of both the data and the computation being performed.
Internally, Spark SQL uses this extra information to perform extra optimizations.
A DataFrame is a distributed collection of data organized into named columns.
It is conceptually equivalent to a table in a relational database.
They allow us process our data using traditional SQL queries,
commonly used functions can be found
here.
They are incredible optimized, but lack type safety;
they use a schema to validate the operations, but the schema is only know in runtime.
However, they're very powerful for data exploratory testing,
since they can infer the schema from the input data.
A Dataset is a distributed collection of semi-structured typed data.
They are strongly typed and can derive they schema from their type at runtime.
However, they require an
Encoder
to serialize the objects.
For that reason, they are commonly used with:
primitive values (including Strings, Dates & Timestamps) and arrays, maps, tuples & case classes of these primitives.
They can be processed either with functional transformations and with SQL queries.
Additionally, the Datasets API provides a powerful feature called
Aggregators,
which allow a simple way to perform parallel aggregations.
Note: A
DataFrameis just aDataset[Row].
In the file Introduction.scala there are example programs using RDDs, DataFrames & Datasets.
RDD: Compute the "Word Count" over a text.DataFrames: "Data Exploratory Analysis" over a CSV file.Datasets: "Aggregation" over a JSON file.
You can run the examples by executing the following command.
$ sbt "run co.com.psl.training.spark.Introduction"In the file Exercise.scala there is the code template for solve an exercise to apply what has been learned.
We have a record of the locations in which the users have been, the record saves the id of the user, the date (with precision in minutes) and the registered location. The exercise consists of obtaining the list of locations (without repeated values) in which each user was in each hour.
Note: you may change the signature of the function to use the abstraction:
RDD,DataFrameorDataset, you prefer.
You can run the exercise by executing the following command.
$ sbt "run co.com.psl.training.spark.Exercise"The output of your program must look like this.
| userid | datetime | locations |
|---|---|---|
| "lmejias" | 2018-12-31T13:00:00 | ["home", "work"] |
| "lmejias" | 2018-12-31T15:00:00 | ["cc"] |
| "dossass" | 2018-12-31T13:00:00 | ["home", "cc"] |
| "dossass" | 2018-12-31T17:00:00 | ["home", "cc"] |