mlir的一个特性是所有ir都支持parse和print, 因此可以方便的使用ir的文本表示来创建对应的mlir模块, 通过文本观察标准的mlir-opt做的各种pass优化, 还可通过cpu-runner实际跑一把.
本repo提供一系列mlir栗子和能运行的转换方式(见运行脚本)
参考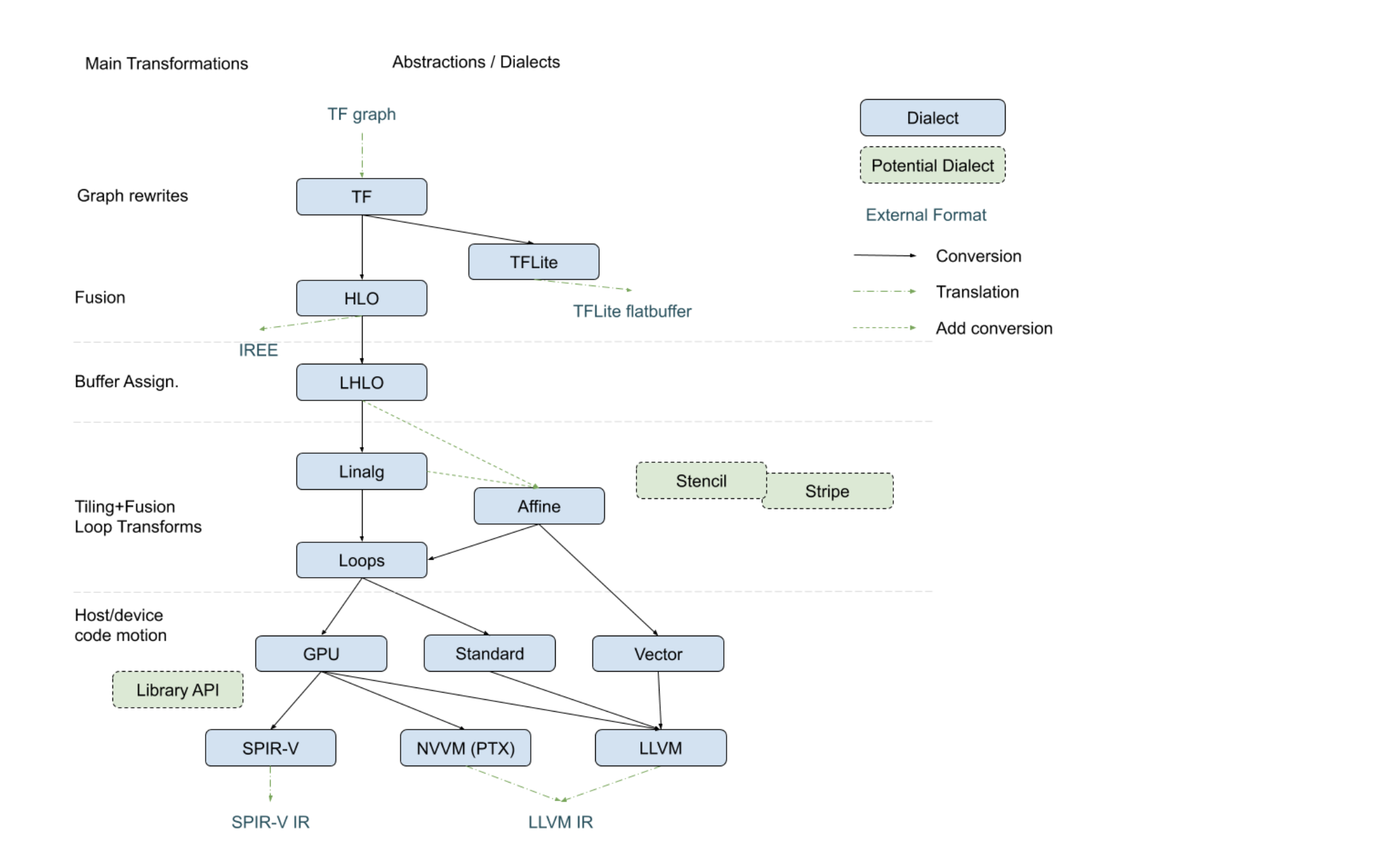 , 从计算来说, 计算从linalg->arith, 控制流从affine->std或linalg->scf->std, 存储从tensor->memref->vector
, 从计算来说, 计算从linalg->arith, 控制流从affine->std或linalg->scf->std, 存储从tensor->memref->vector
打印一个数mlir
%c = arith.constant 1.0 : f32
vector.print %c : f32
return经过-convert-std-to-llvm把标准数值运算Op转为LLVM Op
%0 = llvm.mlir.constant(1.000000e+00 : f32) : f32
vector.print %0 : f32
llvm.return再经过-convert-vector-to-llvm把vector Op转换为LLVM Op
%0 = llvm.mlir.constant(1.000000e+00 : f32) : f32
llvm.call @printF32(%0) : (f32) -> ()
llvm.call @printNewline() : () -> ()
llvm.return这里所有IR符合LLVM标准, 可以使用mlir-cpu-runner运行mlir文件得到输出
填充一个数组并打印mlir
%c = linalg.init_tensor [16] : tensor<16xf32>
%f1 = arith.constant 1.0 : f32
%fill_ct = linalg.fill(%f1, %c) : f32, tensor<16xf32> -> tensor<16xf32>
%fct = bufferization.to_memref %fill_ct : memref<16xf32>
%uc = memref.cast %fct : memref<16xf32> to memref<*xf32>
call @print_memref_f32(%uc): (memref<*xf32>) -> ()经过--linalg-bufferize把linalg的存储由tensor转换为memref, tensor严格遵守单赋值用于各种优化. memref表示一段内存空间, 不遵守单赋值.
%0 = memref.alloc() : memref<16xf32>
%cst = arith.constant 1.000000e+00 : f32
linalg.fill(%cst, %0) : f32, memref<16xf32>
%1 = bufferization.to_tensor %0 : memref<16xf32>
%2 = bufferization.to_memref %1 : memref<16xf32>
%3 = memref.cast %2 : memref<16xf32> to memref<*xf32>
call @print_memref_f32(%3) : (memref<*xf32>) -> ()经过-convert-linalg-to-loops把linalg的控制流转换为scf的for
%cst = arith.constant 1.000000e+00 : f32
%c16 = arith.constant 16 : index
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = memref.alloc() : memref<16xf32>
scf.for %arg0 = %c0 to %c16 step %c1 {
memref.store %cst, %0[%arg0] : memref<16xf32>
}
%1 = memref.cast %0 : memref<16xf32> to memref<*xf32>
call @print_memref_f32(%1) : (memref<*xf32>) -> ()经过-convert-scf-to-std, 把for转换为std版本的条件跳转
%cst = arith.constant 1.000000e+00 : f32
%c16 = arith.constant 16 : index
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = memref.alloc() : memref<16xf32>
br ^bb1(%c0 : index)
^bb1(%1: index): // 2 preds: ^bb0, ^bb2
%2 = arith.cmpi slt, %1, %c16 : index
cond_br %2, ^bb2, ^bb3
^bb2: // pred: ^bb1
memref.store %cst, %0[%1] : memref<16xf32>
%3 = arith.addi %1, %c1 : index
br ^bb1(%3 : index)
^bb3: // pred: ^bb1
%4 = memref.cast %0 : memref<16xf32> to memref<*xf32>
call @print_memref_f32(%4) : (memref<*xf32>) -> ()经过-convert-memref-to-llvm, 把memref的结构体解开,并把对应的访存操作转为LLVM标准操作
%cst = arith.constant 1.000000e+00 : f32
%c16 = arith.constant 16 : index
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
%0 = llvm.mlir.constant(16 : index) : i64
%1 = llvm.mlir.constant(1 : index) : i64
%2 = llvm.mlir.null : !llvm.ptr<f32>
%3 = llvm.getelementptr %2[%0] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
%4 = llvm.ptrtoint %3 : !llvm.ptr<f32> to i64
%5 = llvm.call @malloc(%4) : (i64) -> !llvm.ptr<i8>
%6 = llvm.bitcast %5 : !llvm.ptr<i8> to !llvm.ptr<f32>
%7 = llvm.mlir.undef : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%8 = llvm.insertvalue %6, %7[0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%9 = llvm.insertvalue %6, %8[1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%10 = llvm.mlir.constant(0 : index) : i64
%11 = llvm.insertvalue %10, %9[2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%12 = llvm.insertvalue %0, %11[3, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%13 = llvm.insertvalue %1, %12[4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
br ^bb1(%c0 : index)
^bb1(%14: index): // 2 preds: ^bb0, ^bb2
%15 = builtin.unrealized_conversion_cast %14 : index to i64
%16 = arith.cmpi slt, %14, %c16 : index
cond_br %16, ^bb2, ^bb3
^bb2: // pred: ^bb1
%17 = llvm.extractvalue %13[1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>
%18 = llvm.getelementptr %17[%15] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
llvm.store %cst, %18 : !llvm.ptr<f32>
%19 = arith.addi %14, %c1 : index
br ^bb1(%19 : index)
^bb3: // pred: ^bb1
%20 = llvm.mlir.constant(1 : index) : i64
%21 = llvm.alloca %20 x !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)> : (i64) -> !llvm.ptr<struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>>
llvm.store %13, %21 : !llvm.ptr<struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>>
%22 = llvm.bitcast %21 : !llvm.ptr<struct<(ptr<f32>, ptr<f32>, i64, array<1 x i64>, array<1 x i64>)>> to !llvm.ptr<i8>
%23 = llvm.mlir.constant(1 : i64) : i64
%24 = llvm.mlir.undef : !llvm.struct<(i64, ptr<i8>)>
%25 = llvm.insertvalue %23, %24[0] : !llvm.struct<(i64, ptr<i8>)>
%26 = llvm.insertvalue %22, %25[1] : !llvm.struct<(i64, ptr<i8>)>
%27 = builtin.unrealized_conversion_cast %26 : !llvm.struct<(i64, ptr<i8>)> to memref<*xf32>
call @print_memref_f32(%27) : (memref<*xf32>) -> ()最后通过-convert-std-to-llvm把std的branch和arith的数值运算转换为LLVM标准, 并使用-reconcile-unrealized-casts无视某些未实现的转换就可以成功运行了
前面已经讲了很多底层转换, 目的是把上层IR转换为LLVMIR以达到可以运行的目的. 这里开始只讲上层变换, 目的是完成更多逻辑层面优化
参考elemwise_fuse, 使用tensor和generic描述两个elemwise
%res_tensor = linalg.init_tensor [10] : tensor<10xf32>
%res_mid = linalg.generic {indexing_maps = [#map0, #map0, #map0], iterator_types = ["parallel"]}
ins(%fill_c1, %fill_c2 : tensor<10xf32>, tensor<10xf32>)
outs(%res_tensor : tensor<10xf32>) {
^bb0(%a: f32, %b: f32, %c: f32) :
%4 = arith.addf %a, %b : f32
linalg.yield %4 : f32
} -> tensor<10xf32>
%res_mid2 = linalg.generic {indexing_maps = [#map0, #map0, #map0], iterator_types = ["parallel"]}
ins(%res_mid, %fill_c5 : tensor<10xf32>, tensor<10xf32>)
outs(%res_tensor : tensor<10xf32>) {
^bb0(%a: f32, %b: f32, %c: f32) :
%4 = arith.addf %a, %b : f32
linalg.yield %4 : f32
} -> tensor<10xf32>经过-linalg-fuse-elementwise-ops在tensor和generic层面完成融合(感觉比affine层面融合靠谱)
%7 = linalg.generic {indexing_maps = [#map, #map, #map, #map], iterator_types = ["parallel"]} ins(%3, %4, %5 : tensor<10xf32>, tensor<10xf32>, tensor<10xf32>) outs(%6 : tensor<10xf32>) {
^bb0(%arg0: f32, %arg1: f32, %arg2: f32, %arg3: f32): // no predecessors
%10 = arith.addf %arg0, %arg1 : f32
%11 = arith.addf %10, %arg2 : f32
linalg.yield %11 : f32
} -> tensor<10xf32>矩阵分块是常规优化技巧, linalg层面也提供这种pass, 参考matmul mlir
func @matmul(%arg0: tensor<128x64xf32>,
%arg1: tensor<64x256xf32>, %arg2 : tensor<128x256xf32>) ->tensor<128x256xf32> {
%0 = linalg.matmul ins(%arg0, %arg1 : tensor<128x64xf32>, tensor<64x256xf32>) outs(%arg2 : tensor<128x256xf32>) -> tensor<128x256xf32>
return %0 : tensor<128x256xf32>
}经过--linalg-strategy-tile-pass="anchor-func=matmul anchor-op=linalg.matmul" --linalg-tile="tile-sizes=8", 把m切成8, 每次计算8x256的分块, 实测性能不如不切.... 切成4x16的分块性能也不如不切, 细节没看
%c8 = arith.constant 8 : index
%c128 = arith.constant 128 : index
%c0 = arith.constant 0 : index
%0 = scf.for %arg3 = %c0 to %c128 step %c8 iter_args(%arg4 = %arg2) -> (tensor<128x256xf32>) {
%1 = tensor.extract_slice %arg0[%arg3, 0] [8, 64] [1, 1] : tensor<128x64xf32> to tensor<8x64xf32>
%2 = tensor.extract_slice %arg4[%arg3, 0] [8, 256] [1, 1] : tensor<128x256xf32> to tensor<8x256xf32>
%3 = linalg.matmul ins(%1, %arg1 : tensor<8x64xf32>, tensor<64x256xf32>) outs(%2 : tensor<8x256xf32>) -> tensor<8x256xf32>
%4 = tensor.insert_slice %3 into %arg4[%arg3, 0] [8, 256] [1, 1] : tensor<8x256xf32> into tensor<128x256xf32>
scf.yield %4 : tensor<128x256xf32>
}